오늘날 자동차 산업은 전기, 전자 기술과 함께 급속히 발전해왔다. 과거에 비해 자동차에 탑재되는 전장품의 비율이 증가하고 하드웨어 및 소프트웨어의 복잡도가 증가함에 따라 고장의 확률 또한 증가하고 있다. 소프트웨어의 복잡도, 모듈화, 구현의 용이성 등을 위해서 자동차 업계에서는 이미 AUTOSAR(AUTomotive Open System ARchitecture)라고 하는 자동차 전자제어기를 위한 개발 권고 표준을 정해 이에 따르도록 하고 있으며, 항공우주 분야의 DO178B/254, 산업에 적용되는 EN/ISO13849, IEC61508 등의 표준과 같이 자동차 업계에서는 최근 하드웨어 및 소프트웨어 뿐만 아니라 심지어 전자 제어기 개발 프로세스까지 다루는 ISO26262 (기능안전) 표준을 요구하고 있다.
안전 메커니즘(Safety Mechanism) 정의
가. EE System
1) Analog Input
자동차의 가속 페달과 같은 아날로그 센서신호를 받을 때 Stuck at-fault, DC-fault mode, drift 및 oscillation 등의 문제 발생할 수 있다. 이러한 경우 운전자의 의도와 상관치 않게 잘못된 센서 값으로 인해 잘못된 출력을 발생시킬 수 있다. 이는 결국 safety goal을 만족시킬 수가 없다. 여기에 활용할 수 있는 안전 메커니즘은 두 개의 독립적인 마이크로컨트롤러의 ADC 핀으로 부터 아날로그 신호 값을 읽는 것이다. 두 개의 다른 ADC을 사용하면 plausibility를 검출할 수 있다. 각각의 ADC 유닛으로부터 하나씩의 아날로그 신호를 읽어 들이는 것으로 충분하다. 왜냐하면 두 개의 ADC값을 비교할 때 하나의 잘못된 ADC는 불일치로 판단될 수 있기 때문이다.
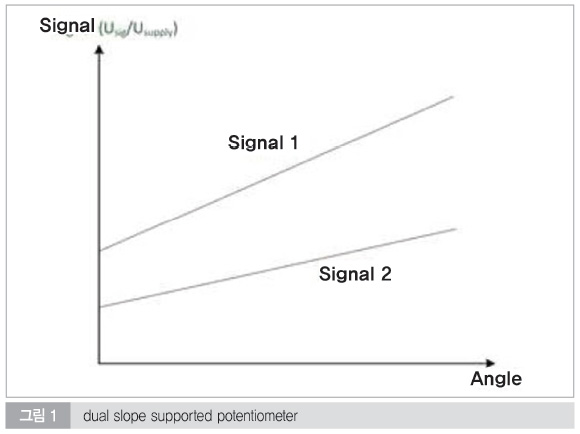
그림 1은 두 개의 독립적인 다른 성향의 커브의 포텐쇼메터들로 이루어진 일반적인 포테쇼메터의 구조를 보여주고 있다. 그림 1에서 보는 바와 같이 커브들은 다른 슬로프를 가지고 있으며 다른 출력 값의 범위를 가지고 있다.
센서 시그널 라인의 그라운드 및 V_ba 와의 쇼트는 잘못된 값을 내줄 뿐만 아니라 두 개의 센서의 실제 값을 비교할 때 일치하지 않는다. 만약에 두개의 센서 시그널이 서로 쇼트된다면 두 개의 센서 아웃풋은 동일한 voltage 값에 의해서 같은 값이 나오게 되는데 이 역시 애초에 설계된 바로 같은 값이 나오게 되면 서로 다른 슬로프를 가진 특성에 위배됨을 검출할 수가 있다.
2) Processing Unit
운전자의 가속하고자 하는 요구를 센서로부터 정확하게 받았다고 해도 CPU의 오류, 레지스터의 비트 플립, 잘못된 주소 참조 등으로 인해 결과적으로 잘못된 판단을 할 수 있다. 이러한 경우 다음의 두 가지 방법에 의해서 이러한 오류를 검출할 수 있다.
드라이버의 요구를 평가하는 코드를 두 번 실행하는 방법이다. 즉, 두 개의 독립적인 코어를 이용해서 아주 짧은 사이클(통상적으로 2 clock cycle)을 두고 실행하는 방법이다. 이를 듀얼 코어 락스텝 기술이라고 한다. 두 개의 코어에서 실행된 결과 값을 하드웨어 비교기가 체크한다. 이 하드웨어 비교기는 각각 실행된 머쉰 코드 명령 값의 결과의 동일성을 체크한다.
운전자의 가속 페달 값의 수신된 신호를 두 번 처리하는 방법이다. 즉, 하나의 코어 상의 두 개의 독립적이고 중복적인 모듈에 의해서 검사하는 방법이다. 그 결과는 비교기로 구현된 소프트웨어에 의해서 검사된다.
3) Error Correction and Detection Codes
자동차의 통신 시스템의 메시지 혹은 ECU 내의 volatile(휘발성) 혹은 non-volatile(비휘발성) 메모리의 데이터 무결성 체크를 위해서 다양한 방법이 자동차 분야에서 사용되고 있는데, 반드시 복잡도가 낮고, 구현이 용이해야 하며, 에러 검출 능력이 좋아야 한다.

Parity, 체크섬, CRC는 에러 수정에는 적합하지 않다. 단지 에러 검출만을 위해 사용된다. 에러 수정을 위해서는 좀 더 복잡한 Reed-Solomon 코드가 사용된다.
가) 패리티비트(Parity bit)
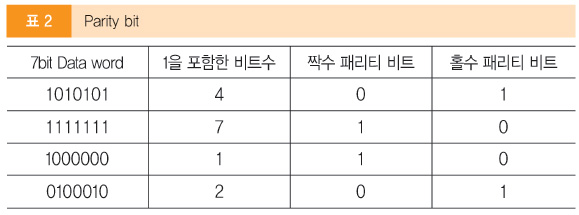
패리티 비트는 정보의 전달 과정에서 오류가 생겼는지를 검사하기 위해 추가된 비트이다. 전송하고자 하는 데이터의 각 문자에 1 비트를 더하여 전송하는 방법으로 2가지 종류의 패리티 비트(홀수, 짝수)가 있다. 패리티 비트는 오류 검출 부호에서 가장 간단한 형태로 쓰인다.
짝수(even) 패리티는 전체 비트에서 1의 개수가 짝수가 되도록 패리티 비트를 정하는 것인데, 이를테면 데이터 비트에서 1의 개수가 홀수이면 패리티 비트를 1로 정한다. 홀수(odd) 패리티는 전체 비트에서 1의 개수가 홀수가 되도록 패리티 비트를 정하는 방법이다.
7비트의 0010110이라는 데이터에서 짝수 패리티가 되게 하기 위해서는 1의 패리티 비트를 붙여 00101101로 한다. 또 같은 데이터에 대해 홀수 패리티 비트가 되게 하려면 0의 패리티 비트를 붙인다. 이렇게 패리티 비트를 정하여 데이터를 보내면 받는 쪽에서는 수신된 데이터의 전체 비트를 계산하여 패리티 비트를 다시 계산함으로써 데이터 오류 발생 여부를 알 수 있다. 그러나 패리티 비트는 오류 발생 여부만 알 수 있지 오류를 수정할 수는 없다.
나) Checksum(체크섬)
체크섬은 parity비트보다 좀 더 향상된 검출 방법으로서 분할된 데이터를 더하여 체크섬 값을 얻고, 이 데이터에 같이 붙여서 보낸다. 수신 측에서는 같은 방식으로 체크섬 값을 계산하여 비교하여, 체크섬이 맞아 떨어지지 않으면 메시지가 손상되었다고 판단한다. 주로 8, 16, 32 체크섬 비트가 사용되며, single bit error와 burst error를 검출할 수 있으며, 에러 수정은 가능하지 않다.
다) Cyclic Redundancy Check (CRC)
CRC는 자동차의 통신시스템에서 오류 검증을 위해서 많이 사용한다. 정해진 다항식이 결정되어 있고, 이것에 따라 송신 쪽에서 계산하여 헤더에 붙여 보내면 수신 쪽에서 다시 계산하고 보내진 CRC값과 비교해서 맞으면 취하고 다르면 재전송을 요청한다.
CAN message는 8byte payload 데이터까지 전송할 수 있고, 더 큰 메시지는 분할되어 전송된다. CAN bus는 8byte payload 데이터를 오류 체크를 위해 CRC-15를 사용한다.
CAN Specification에 따르면 CRC값 생성을 위한 다항식 G(x)는 다음과 같다.
G(x)= x15 + x14 + x10 + x8 + x7 + x4 + x3 + 1
FlexRay는 8byte에서 254byte까지 payload 데이터까지 전송할 수 있고, CRC-11과 해밍디스턴스 D=6 값이 메시지 헤더의 데이터 오류 체크를 위해 사용되고, CRC-24와 해밍디스턴스 D=4값이 메시지 헤더와 payload 데이터 오류 체크를 위해 사용된다.
CRC 값을 생성하기 위한 다항식은 다음과 같다.
G(x)header = x11 + x9 + x8 + x7 + x2 + 1
G(x)header+payload = x224 + x23 + x22 + x19 + x18 + x16 + x14 + x13 + x11 + x10 + x8 + x7 + x6 + x3 + x + 1
Ethernet은 IEEE 802.3에 의해서 payload의 전송 에러 검출을 위해서 CRC-32를 사용한다. 다항식은 다음과 같다.
G(x)=x32+x26+ x23+ x22+ x16+ x12+ x11 + x10 + x8 + x7 + x5 + x4 + x2 + x + 1
소프트웨어의 상위 계층이라면 소프트웨어적으로 구현하고 하위 계층이라면 하드웨어에 의해서 구현하는 것이 일반적이다. 전반적인 오류 검출 성능은 Checksum 보다는 CRC가 더 높으며, CRC는 Shift 레지스터와 XOR 게이트로 하드웨어 구현이 용이하고 오류 검출이 뛰어나 CAN과 같은 자동차 통신에 쓰인다. 반면에 Checksum은 소프트웨어로 구현이 용이하여 보다 상위 계층의 오류 검출 코드로 많이 사용이 된다.
라) Error Correcting Codes(ECC)
ECC는 마이크로컨트롤러의 volatile memory(휘발성 메모리)와 non-volatile memory(비 휘발성 메모리)의 오류를 검출하는데 적합하다. ECC는 읽혀지거나 전송되고 있는 데이터에 대해 오류가 생겼는지를 검사하고, 필요하면 전송 중에 정정될 수 있게 하는 기법이다. 이것은 오류를 검출할 뿐 아니라 정정한다는 측면에서 패리티 검사와는 다르다. ECC는 데이터 속도의 증가와 함께, 점차 데이터 저장이나, 전송을 위한 하드웨어 내에도 적용되고 있다. 하나의 데이터 단위가 RAM이나 ROM에 저장될 때, 그 데이터 단위 내의 비트 순서를 나타내는 코드가 계산되어 그 데이터와 함께 저장된다. 64 비트 길이의 워드 각각에는 이 코드를 저장하는데 필요한 여분의 7 비트가 소요된다. 데이터 단위를 읽어낼 때, 지금 읽으려고 하는 워드의 코드를 원래의 알고리즘을 이용해 다시 계산한다. 새로 생성된 코드와 그 워드가 저장될 때 생성되었던 코드를 비교한다. 만약 두 코드가 일치하면, 그 데이터에는 오류가 없다고 보고, 내보낸다. 그러나 만약 그 코드들이 일치하지 않으면, 코드 비교를 통해 잘못되었거나 빠진 비트들을 결정한 뒤, 그 비트를 정정한다. 그 데이터가 아직 저장 장치 내에 있을 때에는 정정을 위한 시도가 일어나지 않는다. 결국, 그것은 새로운 데이터에 의해 덮어씌워질 것이며, 그 오류들은 일시적이라는 가정 하에 부정확한 비트들은 버려진다. 시스템이 꺼졌다 켜졌다를 계속해서 반복한 후, 같은 저장장소에서 반복되는 어떤 오류는 영구적인 하드웨어 에러를 의미하므로, 반복적인 에러가 나는 위치를 나타내는 메시지가 로그에 기록되거나 시스템 관리자에게 보내어진다. 64 비트 워드 레벨에서, 패리티 검사와 ECC는 같은 수의 여분의 비트를 필요로 한다. 일반적으로, ECC는 적은 비용으로 컴퓨터나 전송시스템의 신뢰도를 증가시킨다. 보통 Reed-Solomon 코드가 사용되는데, 이것은 틀린 비트뿐 아니라 지워진 비트까지를 찾아내어 복원시킨다.
ECC는 통상적으로는 1bit 에러 수정, 2bit 에러 검출로 사용한다. 즉 데이터를 읽을 때 정보가 1bit 깨졌을 경우 알아서 보정을 할 수 있으며, 2bit 이상 깨졌을 경우 틀린 것을 알려 준다. 메모리에 데이터를 쓸 때 미리 ECC 값을 계산하여 Spare 영역에 계산 값을 써넣고 그 후 데이터를 읽어들일 때 다시 ECC 값을 계산하여 Spare 영역에 있는 계산 값과 비교한다. 비교한 결과가 같으면 정상이며 다를 경우 보정 및 에러를 출력하는 방식이다.
4) Supply
파워 서플라이는 주로 독립적인 하드웨어 장치에 의해서 모니터링 된다. 따라서 운용 중에 문제가 생긴다면 safe state로 이동하게 해주는 역할을 한다.
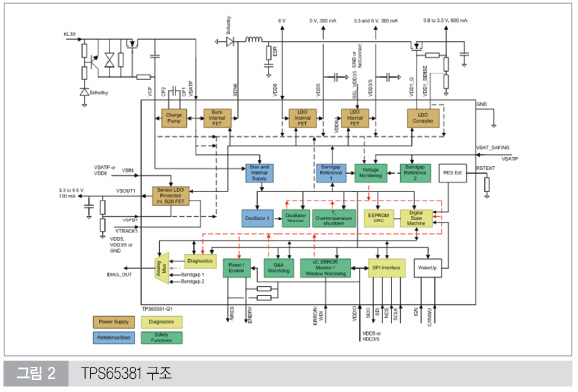
모니터링 하드웨어는 오실레이션 및 아주 짧은 스파이크를 검출할 수 있을 만큼 충분히 빨라야 한다. 또한 커패시터를 마이크로 컨트롤러에 가까이 위치시켜 필터역할을 하게 하면 서플라이 전압의 외란을 보호할 수 있다. 예를 들어, TI社의 TMS570 마이크로 컨트롤러는 그림 2과 같은 TPS6538x와 함께 구현할 수 있다.
5) Temperature
전자 디바이스를 허용된 온도 미만 혹은 초과된 상태에서 운용한다면 동일한 시간 즉, 한 사이클 내에 서로 다른 독립적인 서브시스템에서 고장을 유발할 가능성이 높다. 이러한 잠재적인 고장을 커버하기 위해서 적어도 ECU의 온도를 반드시 모니터링해야한다. 따라서 온보드 온도 체크를 위해서 온도 센서를 적용하여 소프트웨어에 의해서 모니터링할 수 있도록 설계한다.
운영체제 (OS)
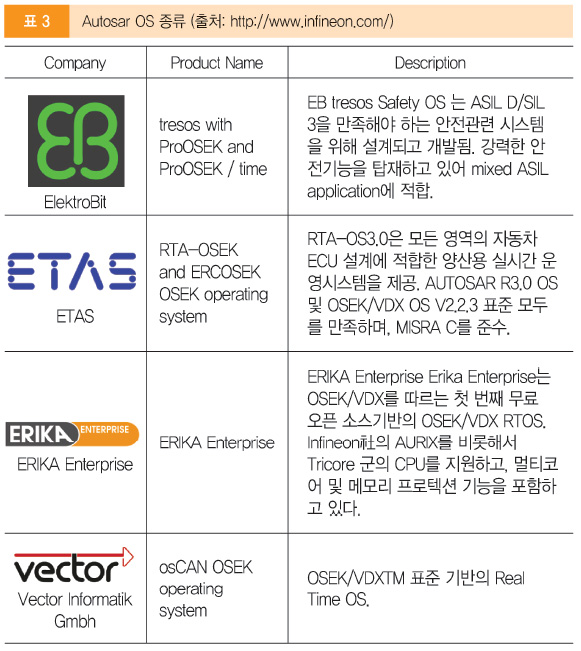
1) Autosar OS
AUTOSAR에서 정의하고 있는 AUTOSAR OS는 전자제어 장치에서 사용 가능한 Real-Time OS이다. 흔히 알려진 다른 OS와는 달리 높은 신뢰성과 효율성을 보장하며, 최소한의 ROM, RAM 리소스를 사용하도록 고안된 운영체제이다.
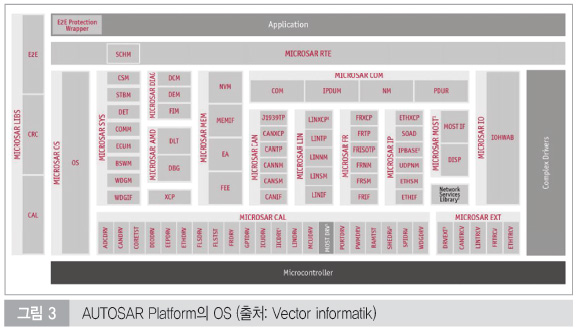
AUTOSAR OS에서는 runtime 상에서 새로운 task를 생성할 수 없다. Build하기 전에 모든 task들이 미리 정의되어야 하며, 동적 메모리 관리 및 task를 제어하기 위한 shell도 제공하지 않는다. OS와 애플리케이션을 통합하고 빌드해서 하나의 binary를 생성한 후, EPROM 혹은 Flash EEPROM에 업로드해서 동작하게 한다.
AUTOSAR 기반에서 설계된 시스템이라면 System Description으로부터 추출된 ECUC Description File을 기반으로 OS를 구동시키기 위한 task, ISR, event, alarm 등을 설정하여 OS의 configuration code를 생성한다. OSEK OS 기반이라면 oil 파일 기반으로 OS의 parameter들이 저장되어 code 생성에 사용된다. 이후 Application에 대한 code와 함께 build 한 후 실제 target에 flash하는 개발 프로세스를 사용한다.
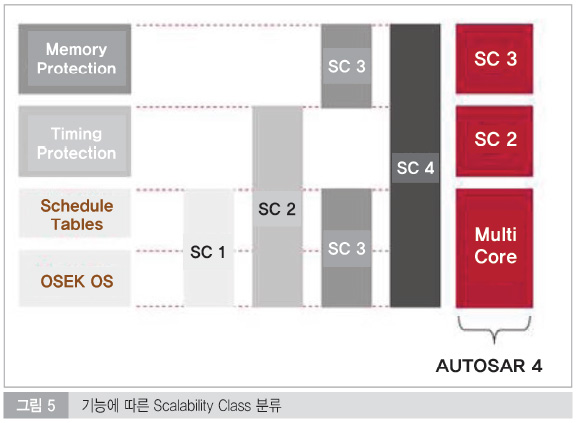
기본적으로 OSKE OS와 Schedule Table을 사용하는 클래스를 SC1이라고 한다. 여기서 Timing Protection 기능을 포함한 것을 SC2라고 한다. 그리고 Timing Protection 기능 대신에 Memory Protection 기능을 포함한 것을 SC3라고 부른다. 마지막으로 SC4 클래스는 이러한 모든 기능을 포함한 것이다. 반면에 Autosar 4에서는 기본적으로 Multi Core OS 기반에서 Memory Protection을 포함하면 SC3, Timing Protection을 포함하면 SC2라고 쓴다.
2) Safety Context
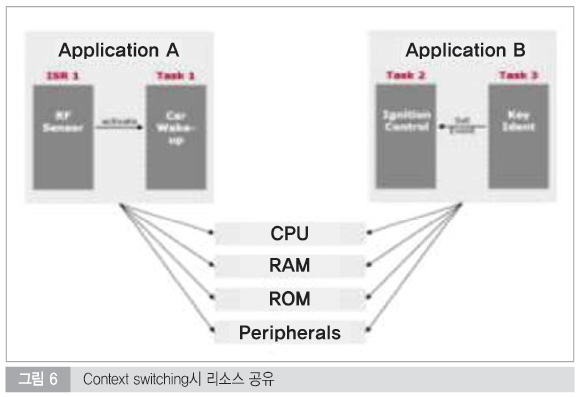
Context Switching이란 하나의 프로세스가 CPU를 사용 중인 상태에서 다른 프로세스가 CPU를 사용하도록 하기 위해, 이전의 프로세스의 상태(문맥)를 보관하고 새로운 프로세스의 상태를 적재하는 작업을 말한다.
한 프로세스의 문맥(context)은 그 프로세스의 프로세스 제어 블록에 기록되어 있다. 문맥을 교환하는 동안에는 유용한 작업을 수행할 수 없기 때문에, 문맥 교환 시간은 일종의 오버헤드라고 할 수 있다. 때때로, 프로세스 스위칭 혹은 테스크 스위칭이라고도 한다.
일단 두 개의 다른 task가 존재하고 하나는 Trusted memory 또 하나는 Non-Trusted Memory 영역을 참조한다고 하면, 하나의 프로세스 혹은 하나의 스레드, 혹은 task가 메모리를 참조하면서 수행을 하다가 다른 영역의 프로세스가 수행하려고 하면 현재 메모리 영역을 보호하면서 상태를 저장하고 다른 프로세스가 끝나면 다시 상태를 복구해야한다.
그림 6에서 Application A에 속하는 ISR 및 Task는 ASIL level로 디자인되었지만 Application B 영역은 QM 수준의 legacy 코드를 사용한다고 가정하면, Context Switching이 이루어질 때, 마이크로 컨트롤러의 리소스들이 비교적 잠재적 오류를 포함하고 있을 가능성이 높은 Application B에 의해서 영향을 받을 수 있다. 이와 같은 잠재적 오류를 피하기 위해서 memory protection 기법 또한 도입해야 한다.
3) Memory Protection
Memory Protection은 컴퓨터 상에서 메모리 접근 권한을 제어하는 방법 중의 하나이다. Memory Protection을 사용하는 가장 큰 목적은 비정상적인 메모리 접근을 차단하기 위한 목적이다. 앞서 설명한 Freedom from Interference 개념과 같이 차량용 소프트웨어 모듈은 실질적으로 모든 소프트웨어 모듈이 높은 신뢰성을 만족할 수 없다. Legacy 코드를 사용하기 때문일 수 있고, 높은 개발 비용 때문에 사실상 모든 모듈이 ASIL-D를 만족하게 개발하기는 상당히 어렵다. 따라서 비교적 낮은 QM 수준의 소프트웨어 모듈이 CPU의 memory 자원을 공유하는 것을 피할 수 없다.
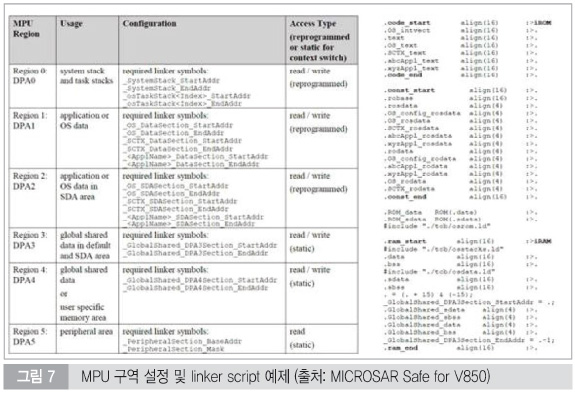
Memory protection 기능은 이러한 가능성을 차단할 수 있다. 이 Memory Protection기능을 사용하기 위해서는 CPU차원에서 MPU(Memory Protection Unit) 기능을 제공하여야 한다. 최근 차량용 마이크로 컨트롤러는 기본적으로 이 MPU를 대부분 탑재를 하고 있어 기능 구현이 가능하다.
안전 모니터링 모듈 (Safety Monitoring Module)
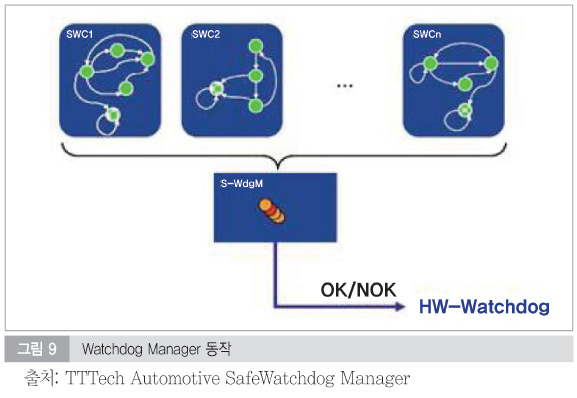
AUTOSAR 4.x 부터 ISO26262를 AUTOSAR에 반영하기 위해 안전 관련 소프트웨어 모듈을 추가했다. AUTOSAR에 정의된 안전 모니터링 모듈은 Watchdog Manger, Watchdog Interface 그리고 Watchdog Driver로 구성되어 있다. 그림 8은 AUTOSAR 환경에서 Watchdog stack들을 보여주고 있다.
Watchdog Manager는 Watchdog Interface와Watchdog Driver를 통해 마이크로 컨트롤러에 내장된 Watchdog을 제어한다. 외부 Watchdog을 사용할 수도 있으며, 최근에는 마이크로 컨트롤러 자체의 오류에 영향을 받을 수 있는 내부 Watchdog 대신에 마이크로컨트롤러와 독립적으로 작동하는 외부 Watchdog을 더 많이 적용하는 추세이다.
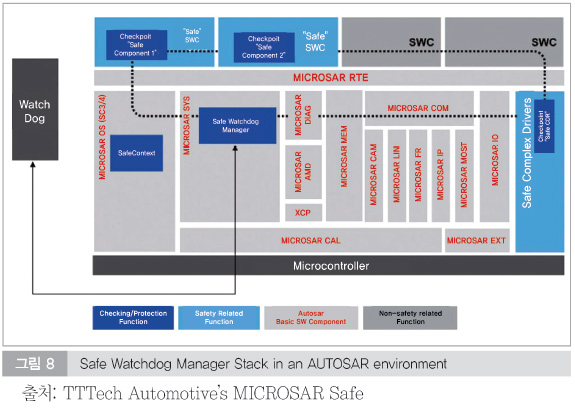
기본적으로 Watchdog Manager stack은 supervised entity(SE)라고 부르는 단위의 프로그램 플로우와 타이밍을 모니터링하는 기능을 가지고 있다. 다음은 Watchdog Manager Stack이 모니터링할 수 있는 소프트웨어 및 하드웨어 오류들이다.
▶ SE가 수행되었지만 실행이 요청되지 않음
▶ 실행이 요청되었지만 SE가 수행되지 않음
▶ SE의 실행이 너무 빨리 혹은 너무 늦게 실행
▶ SE의 실행 시간이 예상 시간보다 길거나 짧음
▶ SE의 프로그램 플로우가 예상과 다름
다음은 설정에 따라 Watchdog Manager Stack에 의해서 가능한 동작을 나타낸다.
▶ Watchdog Manager Stack은 발견된 오류에 대한 정보를 전송
▶ Watchdog 타임아웃이후에 마이크로컨트롤러를 리셋
▶ 마이크로컨트롤러를 즉시 리셋
1) 프로그램 흐름 모니터링 (Program Flow Monitoring)
Watchdog을 이용한 프로그램 플로우 모니터링은 ISO 26262-6(7.4.14)에 의해서 사용을 권장하고 있다. 알고리즘 상의 논리적 오류를 검출하는 것 이외에 전체 시스템에서 잘못된 PC (Program Counter)를 검출할 수 있다. 모니터링 사이클이 수행되는 동안 supervised entity 내의 프로그램 플로우 위반을 검출해서 즉시 Fail Safe 상태로 이동하게 할 수 있으며, tolerance를 부여할 수도 있다. 즉, 미리 정의된 tolerance 값 이하라면 상태 천이를 보류하고 있다가 tolerance 값을 초과하면 상태를 천이시킬 수 있다.
기본적으로 4가지의 상태를 가질 수 있으며, WDGM_LOCAL_STATUS_OK에서 오류 검출이 tolerance를 초과한다면, WDG_LOCAL_STATUS_FAILED로 상태를 천이하고, 일정 reference cycle 동안 오류가 검출되지 않는다면 다시 WDGM_LOCAL_STATUS_OK로 상태를 변경시킨다.
WDG_LOCAL_STATUS_FAILED 상태에서 오류 검출이 일정 reference cycle 동안 계속된다면 WDG_LOCAL_STATUS_EXPIRED 상태로 이동하며, 이 상태에서는WDG_LOCAL_STATUS_OK로 복귀가 불가능하다.
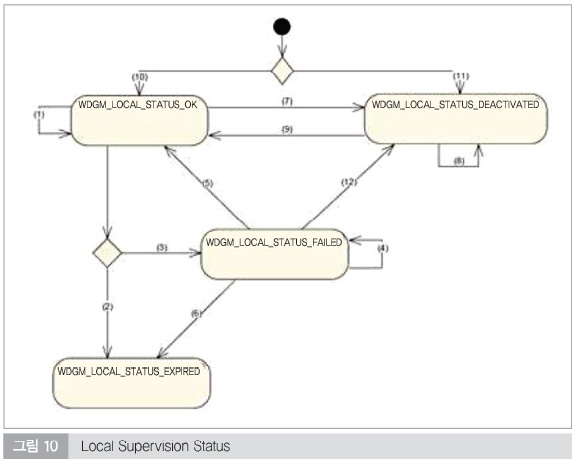
그림 11을 통해 예를 들면, Supervised entity temperature_control은 6개의 checkpoint(타원으로 표시됨)들을 포함하고 있고, 이 checkpoint들은 직접 연결된 천이(화살표로 표시)로 연결되어 있다. 그림 11에서 보는 바와 같이 read_temperature가 수행된 이후에 temperature_needs_correction으로 이동하는 것이 가능하다. 하지만 read_temperature가 수행된 이후에 바로 heater_adjusted_successfully로 상태가 천이되었다면 이러한 경우를 program flow 위반이라고 한다.

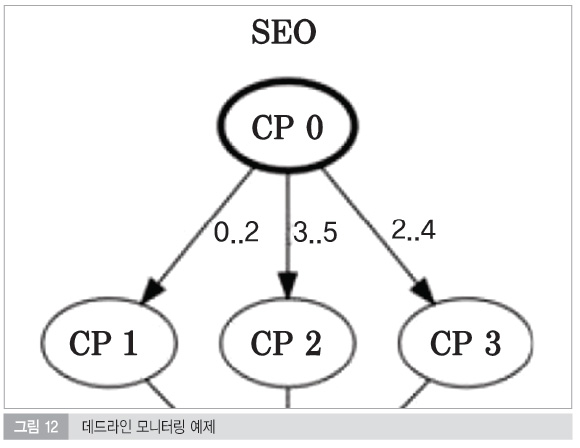
2) 데드라인 모니터링 (Deadline Monitoring)
데드라인 모니터링은 프로그램 플로우 모니터링기반에서 실행 타이밍을 추가로 모니터링하는 기법이다. 즉, 로직의 오류 뿐만 아니라 로직의 흐름 사이에 반드시 만족해야할 타이밍을 설정한다. 두 개의 Checkpoint들 사이에 WdgMDeadlineMin과 WdgMDeadlineMax를 설정하여 Checkpoint가 WdgMDeadlineMin 전에 실행되었거나 WdgMDeadlineMax 이후에 실행되었다면 두 경우 모두 Deadline violation으로 검출이 되며 시스템을 Fail Safe 상태로 갈 수 있게 해준다.
3) Alive Counter Monitoring
Alive Counter Monitoring은 한 SE의 checkpoint(CP)의 주파수를 체크하는 기법이다. 즉, 제어 로직이 없는 경우, 하지만 주기적으로 모니터링되어야만 하는 소프트웨어 컴포넌트에 사용가능하다. 예를 들어, 주기적으로 센서값을 수신하는 경우 미리 정의된 카운터 값으로 모니터링을 하다가 센서 수신의 오류가 있다면 하나의 checkpoint를 카운트할 수 없게 된다. 이러한 경우 적절하게 사용 가능하다.

Wdg M Expected Alive Indications(기대 카운트값)과 Wdg M Supervision Reference Cycle(레퍼런스 사이클)을 1로 가정한다면 한 사이클에 반드시 CP가 한 번만 가능하다는 의미이다. CP를 판단하는 시점은 WdgM_Main Function()이 실행될 때이며, 여기서 예상된 카운터 값이 이미 설정된 기대 카운트값과 비교해서 미만이거나 초과되면 state machine에 의해서 상태 천이가 일어나며, CP가 유실이 지속된다면 설정에 따라 fail-safe 상태로 진입하게 할 수 있다.
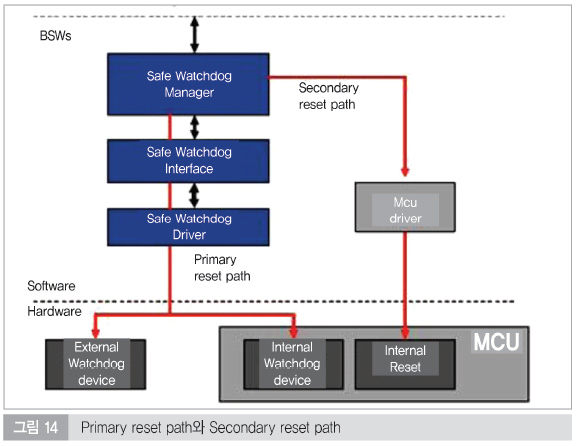
4) Safe State
Safe state는 MCU의 리셋으로 진입가능하다. Wachdog Manager Stack은 신뢰성을 높이기 위해서 두 가지의 reset path를 지원하는데 기본 path는 Watchdog Interface를 통해 Watchdog device를 직접 리셋을 하는 방식이다. 여기서 Watchdog device는 마이크로컨트롤러의 내부 Watchdog 혹은 외부 Watchdog 모두 가능하다. 또한 두 번째 path를 설정에 의해서 사용할 수 있으며, Watchdog Interface 모듈이 실행되는 동안 error를 리턴했을 때 사용할 수 있다. 이러한 error는 외부 Watchdog device와의 통신 에러에 의해서 발생할 수 있다.