최적의 레이어 전송 프로세스
본고에서는 적층 디바이스 레이어의 생성이 가능하도록 IBM에서 개발한 프로세스 단계와 설계 관점에서 논의한다. 자세하게는 최적 레이어 전송 프로세스에 관해서 설명한다. 여기에는 1) 관통-웨이퍼 정렬이 가용한 글라스 기판 프로세스, 2) 본딩 동안 향상된 정렬 허용오차를 위한 산화 퓨전 본딩 및 웨이퍼 휨 보상 방법, 3) 두 개의 적층 디바이스 레이어 사이에서 고종횡비 접촉의 생성을 위한 싱글 다마신 패터닝 및 금속막 방법 등이 포함되어 있다.
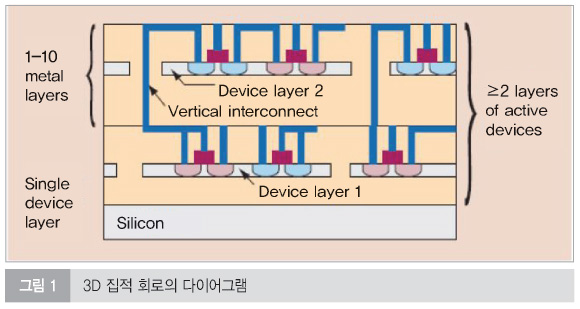
다층 레이어에 수동 소자가 포함된 3D 집적회로는 칩 성능 향상과 더불어 디바이스 패키징의 고밀도화가 가능하다는 잠재력을 가지고 있다. 또한 마이크로칩 구조를 제공하고, 혼성 재질, 디바이스 및 시그널의 집적이 가능하게끔 하기도 한다. 그러나 이러한 장점이 실현되기 이전에는 3D IC의 핵심 기술이 직면한 문제들이 선결되어야만 한다. 좀 더 명확하게, 다층 레이어 수동 소자의 회로 구성에서 요구되는 프로세스는 현재의 첨단 실리콘 프로세싱 테크놀로지와 어우러져야만 한다. 이들 프로세스는 또한 신뢰성, 우수한 수율, 합리적인 비용 등의 제조가능성을 보여야만 한다. 이러한 요구들을 충족시키기 위해, IBM에서는 다기능 회로 레이어 전송에 기반을 둔 3D IC 구축을 위한 구조를 소개했다. 이를 위해 많은 프로세스와 설계 혁신을 이행해 왔다.
CMOS 테크놀로지가 직면한 문제들
IC 테크놀로지의 발달은 성능 및 기능성 향상이라는 두 가지와 더불어, 전력 및 비용 감소 요구로 이어지고 있다. 이러한 목적은 두 개의 솔루션을 이용함으로써 실현되어 왔다. 1) 디바이스 스케일링과 신규 재질 및 프로세싱 혁신의 실행을 통한 배선 와이어의 관계 2) 라우팅, hierarchy, 회로 구축 블록의 배치 등을 변경하기 위한 구조 소개가 이 솔루션들이다. 문제들은 프로세스 스케일링과 관계가 있으며 구조적 스케일링이 논의되어 있다.
▶ 생산라인 전단(FEOL, Front-end-of-line) 스케일링
가속 게이트 길이 스케일링이 게이트 절연체와 접합(junction) 테크놀로지 자체의 물리적 한계가 진행함에 따라, 산화 두께의 연속된 일반적인 벌크-Si CMOS 디바이스의 스케일링, 접합 심도 및 감소 너비 등은 새로운 CMOS 디바이스 구조의 벌크 MOSFET 대체를 꽤 어렵게 하고 있다. 접합 커패시턴스 감소와 body effects 감소로, 고성능을 제공하는 SOI(Silicon-on-insulator) 테크놀로지가 발전되어 왔다. 향후 SOI 두께의 스케일링은 short-channel effect를 감소하고, 대부분의 leakage path를 제거하지만, 이동성을 심각하게 줄여 SOI 스케일링의 확대를 제한한다. 이동성 향상을 제공하는 스트레인 구조의 Si 채널이 실험되어 왔지만, SOI의 장점과 스트레인 구조 실리콘 기술이 혼합된 미래의 구조에서는 더블-게이트 FET와 FinFET를 위해 디바이스 형상과 테크놀로지의 발전을 이용해서 구성될 지도 모른다. 이러한 새로운 합병과 디바이스 옵션을 위한 핵심은 자체 제조에 있어서 어려움이 증가하는 것이고, 평면 구조를 지닌 다양한 설계가 다르다는 것이다.
▶ 생산라인 후단(BEOL, Back-end-of-line)
CMOS 스케일링 트렌드는 제곱 센치미터의 에어리어에 수많은 트랜지스터가 수십 킬로미터의 와이어에 의해 배선되는 설계라는 결과를 초래한다. 와이어는 각각의 트랜지스터에 전력을 전달하고, 저 스큐 동기화 클록(low-skew synchronizing clock)을 제공한다. 그러나 늘어난 와이어링 복잡성 및 고유 게이트 지연을 유지하려는 와이어 지연의 문제가 BEOL 테크놀로지에 있어서 핵심이다. 비록 많은 신규 재질들과 프로세스가 금속 전도성과 유전율(dielectric permittivity) 요구를 충족시키도록 소개되어 왔음에도 불구하고, RC 지연, 낮은 수율, 고비용의 제조과정이라는 결과를 가진 긴 와이어의 배선 금속화가 45nm 테크놀로지 노드를 넘어서 IC의 성능을 제한할 것으로 기대되고 있다.
▶ 구조
전통적인 평면 IC는 floorplanning 선택을 제한해 왔으며, 이 경우 시스템 구조의 성능 증진이 제한된다. 이는 긴 와이어의 네트워크에서 배선 적재 및 클록 분배망(clock distribution)에 이용된 시그널 증폭기(signal repeater) 요구와 관련된 문제를 도출해 낸다. 그러나 증폭기들은 칩에 총 전력 소비의 중요한 일부분을 책임지고 있다. 또한 이미 존재하는 2D IC 설계는 이종 신호(디지털, 아날로그 혹은 RF)의 집적 혹은 여러 테크놀로지들(SOI, SiGE, HBT, GaAs 등)에 적당하지 않을 수도 있다. 추가로 IC 스케일링 추세 때문에 전통적인 CAD 작업과 툴은 증가된 수많은 디자인 사이클(적절한 타임투마킷, 칩 성능 대비 비용)을 요구하고 있다. 그래서 솔루션은 배선 병목현상을 완화할 뿐만 아니라 첨단 디바이스와 혁신 구조에 새로운 방법을 제공하는 방법이 필요해졌다.
3D 집적 회로의 이점
기대되는 여러 솔루션 중 하나가 3D 집적이고 패키징 테크놀로지(수직적 통합으로 잘 알려진)이다. 수동 디바이스의 멀티플 레이어가 3D IC 형성을 위해 레이어 사이를 수직 배선으로 적층된다. 이후 섹션에서는 이 테크놀로지에 대해 자세하게 설명한다. 연속적인 디바이스 스케일링의 부재에도 불구하고, 3D IC는 잠재적인 성능 향상을 제공하기 때문에 3D IC 내부 각각의 트랜지스터는 가장 근접하게 접근할 수 있고, 각각의 회로 작동 블록은 더 높은 대역폭을 가진다. 3D IC의 또 다른 이점은 감소된 와이어 길이/더 낮은 커패시턴스, 월등한 성능 그리고 추가 기능의 가능성 때문에 향상된 패키징 밀도, 노이즈 내성, 향상된 총 전력을 포함하고 있다는 것이다. 이러한 특징에 대해 자세하게 설명한다.
전력
3D 와이어-너비 감소 관련 초기 보고서에서는 3D 집적이 길어진 path와 소형 와이어-너비 분배를 효과적으로 제공한다는 것을 나타내고 있다. 이러한 더 짧아진 와이어는 평균 커패시턴스 부하와 저항을 감소할 것이고, 긴 와이어에서 요구되는 분배기 수도 줄어들 것이다. 분배기를 자체적으로 지지하는 배선 와이어가 총 수동 전력의 대부분을 소모하기 때문에, 2D와 비교해 3D IC 내부의 줄어든 평균 배선 길이는 와이어 효율을 향상시킬 것이고, 총 수동 전력 10% 이상을 감소시킬 것이다.
노이즈
3D IC 내부에서 부하 커패시턴스의 짧아진 배선과 결속성 감쇄는 동시 스위칭 이벤트 때문에 노이즈를 줄게 할 것이다. 짧은 와이어는 또한 시그널 라인 사이에서 덜 민감한 노이즈 커플링을 유발하는 낮은 와이어-투-와이어 커패시턴스를 지닐 것이다. 줄어든 다수의 분배기의 전체적으로 더 짧은 와이어는 또한 더 우수한 시그널 보존을 제공하는 더 낮은 노이즈와 지터를 지닌다.
논리적 스팬
MOSFET 산개가 사이클 당 대량의 전하 이득을 고정하는데 제한적이기 때문에, 증가한 진성 게이트 부하는 외인성 부하 전하(와이어)에 의해 강요된다. 3D IC가 더 낮은 와이어링 부하를 제공함에 따라, 대량의 논리 게이트를 실현할 수 있게 한다.
밀도
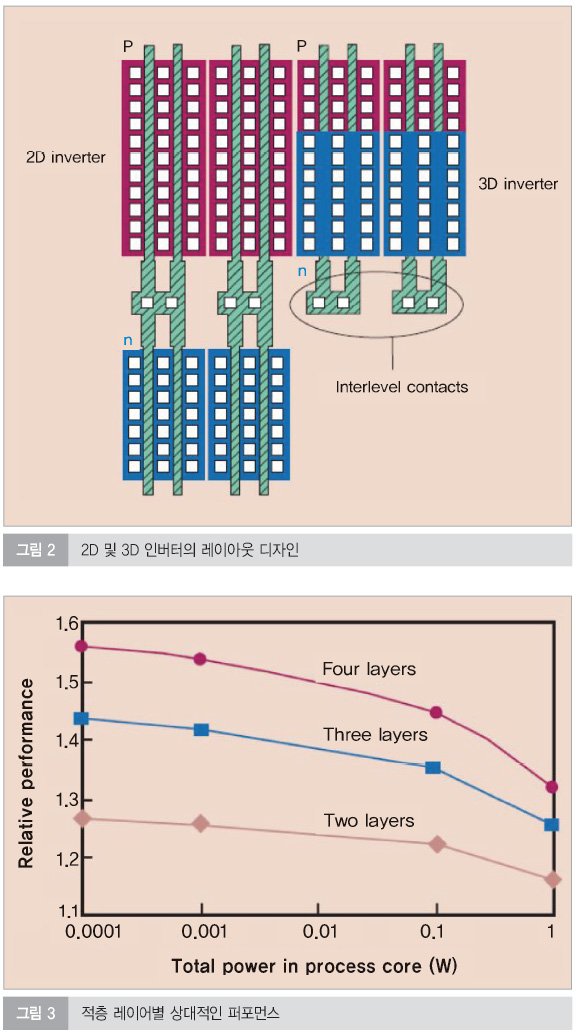
3D의 경우, 수동 소자는 적층될 수 있고, 칩 풋프린트의 크기가 줄어들 수 있다. 전통적인 2D 디바이스 레이아웃에 추가된 3D는 트랜지스터의 패키징 밀도를 향상한다. 이로 인해 그림 2(p-FET 위에 n-FET가 놓여진)에서와 같이 회로 부품들이 다른 부분의 상면에 적층될 수 있다. 총 레이아웃 에어리어가 2D와 서로 다른 인버터 설계를 지닌 3D 표준 셀을 비교했을 때, 3D 셀의 30% 정도의 지역적인 이점에 도달할 수 있다. 회로 요인을 적층하기 위한 능력(풋프린트가 수축하고, 칩의 볼륨 및 무게가 잠재적으로 감소하는)은 무선, 포터블 전자기기 및 군수용 애플리케이션에서 매우 흥미를 끌고 있다. 고밀도와 이로 인한 고속 SRAM 회로가 또한 제작될 수 있다. 예를 들어, 풀업 p-MOS 디바이스가 디바이스 에어리어를 확보할 수 있도록 접근하는 3D 내에서 n-MOS 상부에 적층될 수 있다. 그러나 금속 라우팅이 총 레이아웃 에어리어의 커다란 부분을 차지하기 때문에 총 셀 에어리어 감소는 칩 구조 및 금속 라우팅 설계에 강력하게 의존할 것이다. 성공적인 적층 CMOS SRAM 셀 테크놀로지는 이미 보고되었지만, 이 신장력은 레이어 층간 접촉에 있어서 매우 타이트한 정렬 허용오차 요구에 의해 제한적이다.
성능
3D 테크놀로지는 상부 위 혹은 논리 회부 하부(향상된 대역폭으로 인해 메모리와 마이크로프로세서 간의 커뮤니케이션에 매우 큰 퍼포먼스 이득을 초래하는)에 놓이는 메모리 어레이가 가용하다. 실제로, 대량의 온-칩 메모리가 늘어남(즉, 대부분의 칩이 메모리로 인해 곧 차지할 것)에 따라, 로직으로부터 메모리까지의 path 대기는 로직-메모리 시스템 내부의 제한 요소가 되고 있다. 로직과 메모리의 적층 가능성이 시연되고 있다.
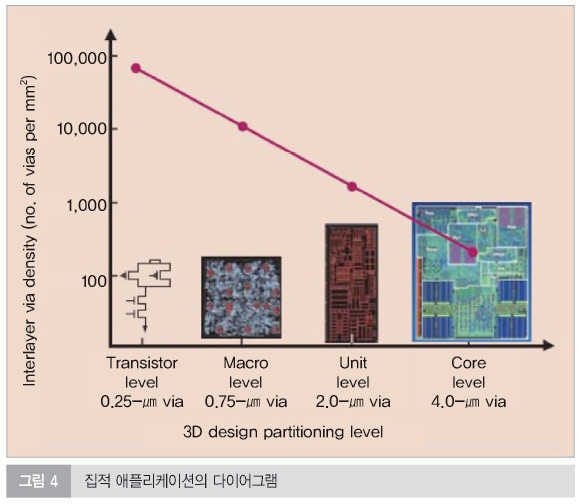
게다가, 하나는 수많은 디바이스 레이어의 작동으로써 최대 시스템 퍼포먼스가 결정될 수 있다. 최대 퍼포먼스는 전력 소실 억제에 의존한다. 전력 억제의 경우, 글로벌 테크놀로지가 최적의 스케일링(수율 최대 수치(예를 들어, 만약 디바이스가 너무 멀리 스케일되면, 너무 많은 전력을 소모하게 된다))이 된다. 단순한 디바이스 모델 및 시스템 의존도가 발전되어 왔고 최적화도 실현되어 왔다. 이러한 레이어링 모델들은 디바이스 레이어를 통한 시그널 패싱 때문에 장애의 영향을 무시할 정도이다. 그림 3에 이를 잘 보여주고 있다. 대략 적층된 많은 회로 레이어의 제곱근으로써 향상한 성능을 지닌 3D 집적의 커다란 잠재적인 장점을 보여주고 있다. 이들 데이터의 핵심은 디바이스의 특성(Vdd, Vt, tox, 게이트 길이, FET 너비, 와이어 하프-피치 및 분배기 공간 등과 같은)이 최대 퍼포먼스를 위해 이미 최적화되어 왔다. 퍼포먼스가 퍼포먼스 = 프로세스 코어 내부에서 초당 총 로직 스위칭 발생수로 성립한 곳에서 그러하다.
다양성
3D 집적은 전통적인 평면 테크놀로지에서 현재 제한적이었던 새로운 요소들의 통합을 허락할 것이다. 이는 새로운 시스템 구조를 포함, 관련된 설계 유연성의 이행을 가능하게 할 것이다. 3D 집적으로 초기 애플리케이션은 하이브리드 회로를 제조하기 위한 다른 테크놀로지의 결합(메모리, RF 확장로직, 아날로그, 광학 및 마이크로일렉트로닉 시스템)이다.
3D IC 제조 테크놀로지
3D IC 제조 테크놀로지는 다양한 프로세싱 시퀀스의 이행에 의해 실현될 수 있다. 다양한 방법 중에서 가장 단순한 방법은 핵심 회로 요소의 레이어 동안 칩-레벨과 웨이퍼-레벨 프로세싱 사이에서 차별화시키는 것이다. 그래서 프로세스는 페이스-투-페이스 혹은 페이스-투-백 접근법을 이용한 레이어 적층이 될지를 결정하는 것으로 인해 더욱이 차별화된다.
칩 적층
패키징을 위한 3D 적층 테크놀로지는 칩-적층 방법이 주로 초점이 되었다. 요즘 많은 3D 패키징 시스템들이 제조되고 있으나 고밀도 메모리 모듈들이 핵심 애플리케이션이다. 전통적으로 3D 패키지는 베어 다이 혹은 멀티칩 모듈(MCM)을 적층한다. 에폭시 혹은 접착제를 이용함으로써 전체 칩이 안정화되고 와이어본딩 기술에 의해 전기적 접촉이 만들어진다. 새로운 3D 패키지는 여러 개의 밀리미터 길이로 된 주위의 배선을 이용한다. 그러나 적층 레이어 간의 짧아진 링크(수 백 미크론)를 지닌 더 높은 배선 밀도는 칩을 관통하는 전도성 수직 관통전극을 결합함으로써 이미 증명되어 왔다. 3D 패키징은 3D IC와 비교했을 때 배선 패턴 기하학과 정렬 정확도 요구를 완화해 왔다. 그래서 3D IC를 위해 최적화되는 핵심 프로세스 테크놀로지 요소는 고밀도, 소형-치수의 레이어 간 접촉을 위한 방법이 있다. 칩-투-칩 및 칩-투-웨이퍼 방법들이 이 목적을 실현하기 위해 이미 이용되어 왔다.
웨이퍼-스케일 제조
3D IC의 웨이퍼-레벨 적층은 칩-적층 기술보다 더 비용효율적인 솔루션으로 적용 가능하다. 3D IC 웨이퍼-스케일 테크놀로지(현재 200mm, 곧 300mm 옵션)는 향상된 설계 유연성을 제공하는 잠재적인 이점을 가지고 있다. 그 후 많은 핵심 프로세싱 단계들이 다이 레벨에서 발전되지 않았다. 3D 회로 집적의 웨이퍼-스케일을 위한 두 개의 초기 구조가 있는데, ‘bottom-up’과 ‘top-down’가 그것이다.
Bottom-up 웨이퍼-스케일 제조
Bottom-up 방법의 경우, 레이어 프로세스는 순차적이고 웨이퍼 적층이 요구되지 않을 수도 있다. 좀 더 자세하게, 대부분의 bottom 레이어는 표준 CMOS 테크놀로지를 이용해 최초에 만들어졌다. 두 번째 Si 레이어의 형성에 따라 두 번째 레이어 위에 디바이스 제조가 진행된다. 추가적인 레이어들은 비슷한 형식으로 top면 위에 올려 질 수 있다. 그 후 Si 레이어들이 고체위상결정화(SPC, solid-phase crystallization), 게르마늄 혹은 니켈, 측면과성장(lateral overgrowth) 혹은 새로운 Si 구조를 제공하기 위한 웨이퍼-본딩 기술의 이전 등과 같은 새로운 방법의 실행을 적용, 추가적인 웨이퍼 적층 없이 제조된다. 후자 방법은 싱글-크리스털 실리콘을 제공하고 첫 번째 방법과 비교해 향상된 디바이스 퀄리티 결과를 보여준다. 그러나 기본 IC 레이어 내부의 우수한 퍼포먼스를 유지하도록 제작되는 열 예산(thermal budget) 제한이 이들 모든 테크놀로지와 관계가 있다.
Top-down 웨이퍼-스케일 제조
Top-down 방법의 경우, 멀티플 2D IC 회로는 평면적으로 제조될 수 있고, 그런 후에 3D IC 형태로 어셈블리된다. 이러한 방법은 각 레이어의 퍼포먼스 최적화 및 적층 이전에 자체의 기능적 검증을 가능하게 한다. 그리고 수용할만한 수율 및 더 낮은 제조비용의 결과를 초래한다. 이종 테크놀로지의 레이어가 밀접하게 적층된 애플리케이션에서 실제로 매력적이다. Top-down 3D IC 테크놀로지의 핵심 프로세스는 고품질, 저온 본딩(<400℃)을 포함하고 있어서 후공정 재질(금속 및 low-k)은 이미 구조의 일부분, 타이트한 정렬 허용오차, 디바이스 레이어 사이에서 접촉의 집적, 하이 프로세스 신뢰성 등이 될 수도 있다.
3D IC 적층
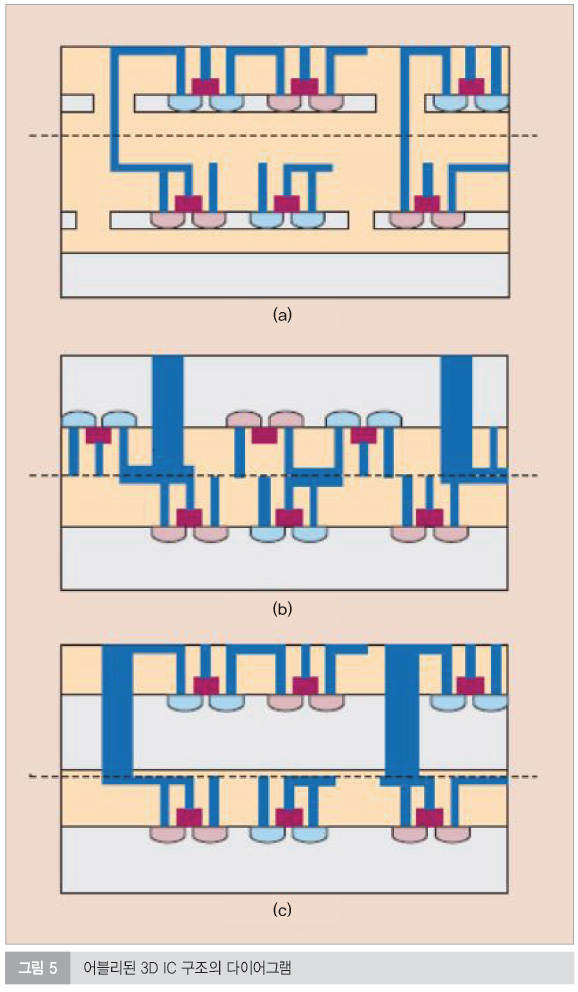
그림 4에서 보는 바와 같이, 3D IC 구조는 또한 레이어된 회로 디자인의 일부분에 따라 특정지어질 수도 있다. 좀 더 자세하게는, 3D 통합은 애플리케이션별 제작이 가능하고, 개념상으로 이는 디바이스, 회로, 매크로, 회로 다기능 유닛 혹은 칩들의 적층 레이어 분할이 가능하다. 3D 애플리케이션 혹은 파티션 레벨에 의존하는 그림 4에서 보는 바와 같이, 특정한 I/O 혹은 인터레이어 비아 밀도가 이뤄질 수 있다. 게다가, 적층 이후 첫 번째 레이어의 top 부분과 관련해 두 번째 레이어의 top 부분의 위치에 따라, 만약 두 개의 top이 서로 각각 직면하면, 프로세스는 ‘face-to-face’로써 묘사될 수 있거나 혹은 그렇지 않을 경우에는 ‘face-to-back’이 된다. face-to-face와 face-to-back 옵션을 이용한 3D IC 제조에서 가장 전망있는 방법들을 그림 5에 나타냈고, 이러한 어셈블리 테크놀로지의 특징들을 표 1에 담았다. 일반적으로 이들 옵션들은 칩-투-칩, 웨이퍼-투-웨이퍼 및 칩-투-웨이퍼 3D IC 제조에 적용될 수 있지만 특별한 프로세스 플로우는 특수한 칩-레벨 혹은 웨이퍼-레벨 테크놀로지에서 없어질 수도 있는데, 이것은 특별한 애플리케이션에서 자주 적용되고 있다.
그림 5(a)에서는 디바이스 레이어 사이의 거리 간격의 구조가 레이어 사이의 전체 Si 서브스트레이트를 제거함으로써 최소화됨을 보여주고 있다. 디바이스 레이서 사이의 본딩이 블랭킷 유전체 퓨전 본딩 혹은 점착 인터레이어의 사용을 통해서 이뤄졌다. 그 후 인터레이어 전자 접촉이 형성되었다.
그림 5(b)는 face-to-face 본딩 옵션을 보여주고 있다. 레이어 간의 고밀도 Cu-Cu 본드 링크 제작이 효과적이지만 패키지 밖으로 시그널을 빼기 위해 딥 비아가 요구된다. 그림 5(c)의 구조는 관련된 정렬 허용오차 사이에서 가장 커다란 인터레이어 비아 치수 및 가장 낮은 비아 밀도를 전형적으로 가지고 있다. 구조의 선택 및 제조 방법은 특별한 목적과 3D IC 테크놀로지의 애플리케이션에 전적으로 의존한다.
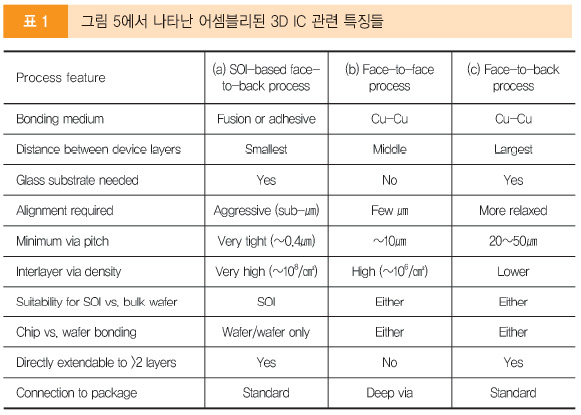
IBM의 3D 어셈블리 구조(표 1, (a) 참조)는 적층 디바이스 레이어 간의 짧은 거리, 고밀도 배선 및 매우 적극적인 웨이퍼-투-웨이퍼 정렬 요구를 지님을 설명하고 있다. IBM의 방법을 이용하면, 진귀한 n-FET와 p-FET 레이어들이 3D IC 프로세스에서 모든 이점을 얻을 수 있도록 적층될 수 있다. 이러한 구조 제작을 위한 프로세스 플로우가 그림 6에 나타나 있다. 엄격한 디자인 요구를 가지고, 핵심 프로세스 최적화는 최신 디바이스 간의 레이어 접합의 발전에 초점을 뒀다.
3D IC 테크놀로지의 핵심들
최종 3D IC 구조의 독립을 위한 어셈블리 방법은 4개의 핵심 테크놀로지 영역의 통합(웨이퍼의 박막화, 디바이스 간 레이어 정렬, 본딩, 레이어 간 접촉 패터닝)을 항상 포함한다. 적읓 레이어들을 통해서 고밀도 I/O 시그널을 위한 추가 문제는 정렬 허용오차에 영향을 미치는 본드 레이어 간의 열적 미스매치가 부각된다. 또한 고성능 CMOS 디바이스의 열 손실은 이미 2D IC에서 개념이 잡혔다. 3D 회로의 경우, 열 분산과 셀프 히팅이 큰 이슈가 된다. 이러한 3D IC 통합 도전의 모든 것은 새로운 재질과 프로세스 혁신을 요구한다. 이에 대해 IBM의 솔루션을 설명한다.
웨이퍼 박막화
기계적인 연마, 광택, 플라즈마에 기반 한 기술들 혹은 wet etching은 얇은 200mm 실리콘 웨이퍼 신뢰성을 실험했다; 20㎛ 두께. 벌크 Si의 제거를 용이하게 하기 위해, 최근 IBM 3D IC 작업의 탁월한 특징은 SOI와 글래스 서브스트레이트의 이용이다. 산화막(BOX, buried oxide layer)은 고성능 최신 IC 테크놀로지에 적용이 가용한 서브스트레이트 박막화를 위한 식각 정지를 제공한다. 좀 더 자세하게는, SOI 웨이퍼 내에서의 산화막은 Si 서브스트레이트(글래스 서브스트레이트 적용과 결합된)의 제거를 위한 선택적인 식각 정지를 제공한다. 이는 향상된 정렬 성능(그림 6 참조)을 가용하게 한다. 양쪽은 디바이스 간의 가장 짧은 거리가 성립됨의 의미를 제공하는 매우 간단한 레이어-이송 프로세스의 특징이 있다. 글래스 캐리어 위의 최종 ‘데칼(decal)’ 구조는 Si 제거된 모든 벌크를 가지고 있다; 이들 금속화 레벨에서의 요구가 적용된 디바이스 레이어에서만 분명한 적층을 만든다. 그래서 ‘관통-웨이퍼’ 정렬 프로세스를 가능하게 한다.
정렬
표준 정렬 방법론은 front-side와 back-side 양쪽 모두의 정렬 전략을 허락한다. 미래 고밀도 3D IC용 초기 도전은 하이-레벨 외로 디자인 제조를 위한 높은(서브미크론) 정렬 허용오차의 요구이다. 현재 가용한 상업적 정렬 툴을 이용한 테스트에서, ~1.0㎛의 3시그마(3σ) 수치는 관통-웨이퍼 정렬 전략을 이용해 현재 얻을 수 있는 최상의 정렬 정확도이다; 이는 비투명성 정렬 방법(back-side 정렬 전략)으로부터 얻어진 최상의 결과보다 1.0㎛ 낮다. 게다가 다층 적층 박막 IC 디바이스 레이어의 경우, 시그널 감쇄는 글래스가 예상되지 않음을 통해서 정렬을 야기했고, 좋은 정렬이 쉽게 이뤄진다. 만약 비투명성 캐리어가 적용된다면, Si를 통한 파장 의존형 시그널 감쇠는 정렬 정확도가 하락할 수도 있다(특히, Si가 존재한 레이어의 경우 40㎛보다 두껍다). 그래서, Si 내의 레졸루션과 투명도 사이의 트레이-오프는 비투명성 웨이퍼(CTE가 실리콘에 일치된 글래스의 적용에 의해 회피되는)에 진정한 도전을 제안한다.
레이어 두 개의 CTE 내부 어려움 때문에 정렬 에러가 실내 온도에서 산화-퓨전 본딩을 이용한 SOI 기반 face-to-back 프로세스를 최소화된다. 다른 본딩 방법을 비교했을 때, 산화-휴전 본딩은 확실한 우위를 보였다(표 2 참조). 정렬되는 동안 실내 온도에서 웨이퍼에 고정시키기 때문이다. 접합을 강력하게 단련하는 포스트-본딩 동안에 증가한 온도를 볼 수 있었으나 정렬 정확도가 변하지는 않았다. 대조적으로 Cu 본딩이 고온에서 발생되기 때문에 극도로 우수한 온도 컨트롤이 유지되어야만 한다. 점착 레이어를 지닌 본딩을 이용한 정확도는 본딩 프로세스(온도 및 컴프레셔 사이클) 동안에 접착제가 점성을 띨 수 있기 때문에 경감될 수도 있다. 그래서 정렬 패턴 이동의 원인이 되기도 한다. 최신 리소그래피 툴의 플레이스먼트 에러가 <0.02㎛라는 것과 이것이 정렬 정밀을 제한하지 않는다는 것도 알 수 있었다.
대량의 정렬 에러는 웨이퍼의 휘어짐을 야기한다. 모든 프로세싱 단계는 때때로 수백 미크론으로 웨이퍼를 휘어지게 변한다. 최상의 정렬 결과를 얻기 위해 휘어짐은 정렬되는 동안 200mm 웨이퍼의 경우 20㎛보다 덜 휘어져야 된다. 이 같은 휘어짐을 유지하기 위해, 계수식 압축응력(counter-pre-stressed) 필름의 침전과 같은 보상 방법이 본딩 단계 이전에 이행되어 왔다. 유사하게, 표면 매끄러움(surface smoothness) 및 로컬 평탄화(local planarity)들은 고-정확도 정렬에 위험요소이다. 이들은 정렬 마크 구조에 초점을 두는 정렬 툴의 확학 성능에 영향을 미친다.
본딩
모든 본딩의 방법의 경우, 접착 인터페이스의 품질은 표면 거칠면과 청결도에 매우 의존한다. 실제로, 퓨전 본딩은 원자적으로 부드러운 표면을 요구한다. CMP(chemical mechanical polishing)와 젖음성 화학 표면 처리기술의 결합은 청결도 측정과 본딩 표면 반응을 위해 본딩 이전에 자주 적용되었다. 클리닝 절차와 post-deposition 애널링 시퀀스가 본드 강도를 조정하는데, 이들은 본딩 인터페이스 시에 보이스의 형성을 격감시키고, 모든 접착 재료에 최적화되어야만 한다. 좀 더 자세하게는 산화-표준 본딩 프로세스의 경우, 본딩 전에 산화(post-deposition) 내에서 -OH 그룹 총괄 농도의 감소가 본딩 애널 동안 부산물 방출을 합병하기 위해 산화의 성능을 강화하고, 결함 없는 본드 인터페이스를 얻는 중요한 것이다.
그림 7에서는 산화 퓨전에 의해 접합된 두 개의 SOI CMOS 디바이스 레이어의 종단면 TEM 이미지를 보여주고 있다. 퓨전-접착 표면을 위한 표면 RMS(root mean square) 거친면 요구는 매우 엄격(<1.0nm)했고 쉽게 얻을 수 없기 때문에 많은 연구자들이 metal-to-metal 본딩 옵션으로 방향을 돌렸다. 이는 이들 RMS 거친면 사양이 높을(<20nm) 수 있기 때문이다. 그런데 metal-to-metal 저온 본딩 프로세스의 단점은 이후 프로세싱 단계 시 고강도의 본드와 안정적인 인터페이스를 위해 고밀도의 패턴이 요구된다는 것이다.
화학 중합체 혹은 절연체 글루(glue) 레이어를 적용한 본딩은 최소 엄격한 표면 평탄화 요구를 가지고 있으나, 점착 글루의 적용은 본딩 동안 이들 레이어의 이동을 유발할 수도 있어서 정렬 허용오차(표 2 참조)가 제한된다. 이 같은 모든 본딩 방법의 온도는 포스트-CMOS FEOL 프로세스의 경우 전통적으로 ~450℃인 각 기능별 레이어의 열 제한과 조화되었다. 점착 인터페이스(점착 강도, 보이드 함유 및 청결도)의 품질이 레벨 간 비아의 제조에 있어서 고수율을 보장하는데 중요하고, 접착 디바이스 신뢰성에 있어서 핵심 요인이 될 것이다.
인터-디바이스-레이어 비아 제조
그림 5에 나타난 3개의 모든 구조의 경우, 3D IC 테크놀로지는 고종횡비(AR, high-aspect-ratio) 비아의 형성을 요구한다. 이러한 비아 제조를 위한 패터닝 및 금속화 공정(플라즈마 에치, 금속 충진, CMP)은 다는 BEOL 프로세스 전략과 융합되어야만 한다. 모든 금속화 기술들은 비아의 최대 종횡비에서 제한 사양이 되고, 그래서 각각의 레이어에서 수동 및 능도 디바이스의 레이아웃 측면에서 디자인이 제한될 수도 있다. 앞서 서술한 바와 같이, SOI 서브스트레이트 내의 BOX 레이어는 매우 타이트한 허용오차를 지닌 디바이스 레이어 두께의 이송을 컨트롤하기 위해 사용되곤 했다. 이 경우 단지 최소 미크론이 위치된 레이어의 수직적인 적층을 가능한 웨이퍼 간 비아의 효과적인 종횡비를 최소화한다. 3D IC의 총체적인 잠재력을 이용하기 위해 서브미크론 직경 치수의 비아들이 최신 FEOL 테크놀로지들과 조화로워 지도록 요구되고 있다. 그래서 고성능 CMOS 디바이스를 적층함으로써 제작된 3D IC의 성능 및 최종 실행능력이 본딩 정렬 허용오차, 디바이스 레이어에 접촉한 고횡종비 비아 서브미크론의 구조적 및 전기적 통합에 결정적으로 의지한다.

그림 8에서는 싱글 다마신 프로세스를 이용, 고종횡비(6:1<AR<11:1)의 3D IC Cu-충진 비아의 서브미크론 배선 제조 성능을 보여주고 있다. 비아 프로파일, 금속 라이너 및 Cu 도금 프로세스가 이들 고종횡비 구조의 적합한 충진을 얻기 위해 표준 BEOL 비아 형성 시퀀스로부터 약간 변경되었다. ~0.4㎛의 bottom 직경, 높이 >1.6㎛ 및 거의 86도의 측면 각도의 가장 작은 비아들은 >108비아/㎠의 고밀도 비아와 동일한 0.4㎛ 피치 위에 형성될 수 있다. ~0.14㎛×0.14㎛의 바텀 critical dimensions(CD)를 지닌 비아는 0.13㎛ CMOS BEOL 테크놀로지와 상응하나, 3D IC 내에서 인터레벨 비아의 더 높은 고종비 때문에 이들의 저항은 전형적인 백엔드 비아의 그것 보다 2~3배 더 높게 기대된다. 톱 및 바텀 웨이퍼의 최초 금속 레벨과 관련한 3D 비아 체인의 링크 당 저항의 측정은 링크 당 ‘2-4Ω의 저항 값이 나타났고, 100~10,000비아를 가진 비아 체인에서 좋은 수율이 나타났다. 이는 접합 인터페이스를 통한 성공적인 금속화 프로세스를 확인하게 했다. 게다가 프로세스 최적화가 더 길어진 체인 길이에 수용할 만한 수율을 달성하기 위해 필요해 졌다. 그러나 한 가지 알아야 할 점은 이러한 고밀도 비아들은 거의 사용되지 않고 있다는 것이다. 이는 상위 디바이스 레이어 위에 수동 회로에 의해 차지되는 공간과 정렬 문제 때문이다. 이 프로세스가 초고밀도를 설정하는 기술로 도식화되었음에도 불구하고, 재질을 이용한 레이어와 프로세스 사이의 낮은 기생 링크가 이전 제조된 회로도와 호환된다.
정렬 정확도는 0.5~2.5㎛의 범위로 제조된 다양한 디바이스 회로의 신뢰할만한 배선을 요구하고, 성공적으로 이뤄져왔다.
열 손실
디바이스의 온도 상승은 2D SOI 테크놀로지에서 이미 주요 관점이 되었다. BOX 레이어의 약한 열 전도성 때문에, 트랜지스터내에서 80~120℃/㎽/㎛ 너비의 열 상승은 이미 보고되었다. 추가로, 열 상승은 디바이스 성능 변화의 원인이 되고 아날로그 회로 내에서 일치하기 매우 어려울 수 있다. 또한 클록 버퍼의 성능은 디바이스 온도 상승에 영향을 받는다. SOI 및 벌크 디바이스의 경우, 정션 온도에서 각 10℃ 상승하면 상대적으로 1.2% 및 1.32%로 클록 버퍼 성능이라는 계산이 나온다.
Pulsed I-V, body-contact diode, 폴리Si 저항 및 subthreshold slope methods 등의 다양한 테스트들이 2D SOI 트랜지스터내의 온도 측정을 위해 사용되곤 했으며, 3D IC 테스트에도 적용될 수도 있다. 3D 구조의 감소된 표면적 대비 볼륨 비율은 파워 밀도내 상승을 필연적으로 이끌 수 있을 것이고, 고성능 칩 고유의 방열에 잠재적으로 영향을 미칠 수도 있다. 그래서 열 경도와 로컬 방열을 최소화하기 위한 열-손실 구조를 이용한 일부 애플리케이션의 경우에는 요구될 수도 있으나, 인터레벨 배선 레이아웃과 3D 칩의 설계에 영향을 미칠 수 있다.






